What we do
TCS Research

TCS Research: Inventing to build sustainable futures
Highlights
- Financial statements are an obvious choice to create misinformation concerning the true financial health of a company.
- While auditors often detect instances of misinformation in financial statements, the audits – being effort-intensive and somewhat subjective – are not always foolproof. We explore unsupervised machine learning techniques – such as anomaly detection and clustering – for assisting auditors by automatically detecting likely instances of misinformation in financial statements.
- Such automated AI-based assistance helps the auditors in focusing the auditing efforts more effectively towards finding likely instances of misinformation in the reported financial data. The techniques do not need any labeled data of previously known instances of misinformation.
On this page
On this pageinpage
What is financial misinformation?
Misinformation is defined as a deliberately created piece of information which can be viewed as deceptive, distorted, malicious, biased, inaccurate, unreliable, unsubstantiated, unverified, false, or fabricated. It can manifest in various forms such as text documents (e.g., news articles, product reviews, emails, resumes) or structured data.
The assets (e.g., cash, deposits, shares, property, factories, inventory, etc.) and liabilities (e.g., debts, taxes, rents, bills, accounts payable, etc.) of an organization continuously change over time due to business transactions, operations, and other activities. The Financial Accounting domain has established several standardized, semi-structured financial statements (FS), such as the balance sheet (BS), profit and loss statement (P&L), cash-flow statement, and tax returns, which companies use to summarize their financial performance over a year. Accountants adhere to generally accepted accounting principles (GAAP) and international financial reporting standards (IFRS) while preparing FS. Auditors review the FS contents and certify that the FS are free from material misstatement and are fair, accurate, and comply with the relevant accounting standards.
The damage financial misinformation can cause
Contents of FS are critically examined from various viewpoints by investors, creditors, suppliers, banks, tax authorities, and the general public for different reasons, including corporate governance, credit evaluation, risk assessment, taxation, and investment decisions. Due to the significance of FS, there are obvious motivations to create misinformation, such as concealing, omitting, or falsifying data to misrepresent the actual financial condition of a company. Ulterior motives for falsifying FS include reducing tax liabilities, boosting investor confidence, reassuring creditors, and concealing fraud. Numerous questionable accounting practices like expensing early, deferring revenue, underreporting book value, understating liabilities/expenses/losses, and overstating assets/revenues/profits are observed in financial reporting.
Estimating the prevalence of misinformation in FS is challenging. Such misinformation can have severe repercussions for stakeholders, including siphoning of money or goods, inability to compensate employees or suppliers, loan defaults, losses for investors, tax revenue losses for the government, damage to trust/reputation/goodwill, and even bankruptcy. Several high-profile corporate bankruptcies, like Satyam, Enron, and WorldCom have been traced to undetected accounting misinformation. Such scandals have prompted governments to implement laws, such as The Sarbanes-Oxley Act of 2002 in the US, explicitly designed to improve financial reporting and public information disclosure.
Auditors and forensic accountants examine various data sources and records to uncover potential misinformation in the figures reported in FS (Table 1). They have developed a variety of investigative techniques to verify the sources of the reported numbers in FS and identify misinformation. Although auditors often detect instances of misinformation in FS, audits can be labour-intensive and somewhat subjective, making them not entirely reliable; moreover, a lack of auditor independence can also result in subpar audits. Given the demanding and subjective nature of audits and forensic accounting investigations, many machine learning (ML) techniques have been developed to detect FS that may contain some misinformation.
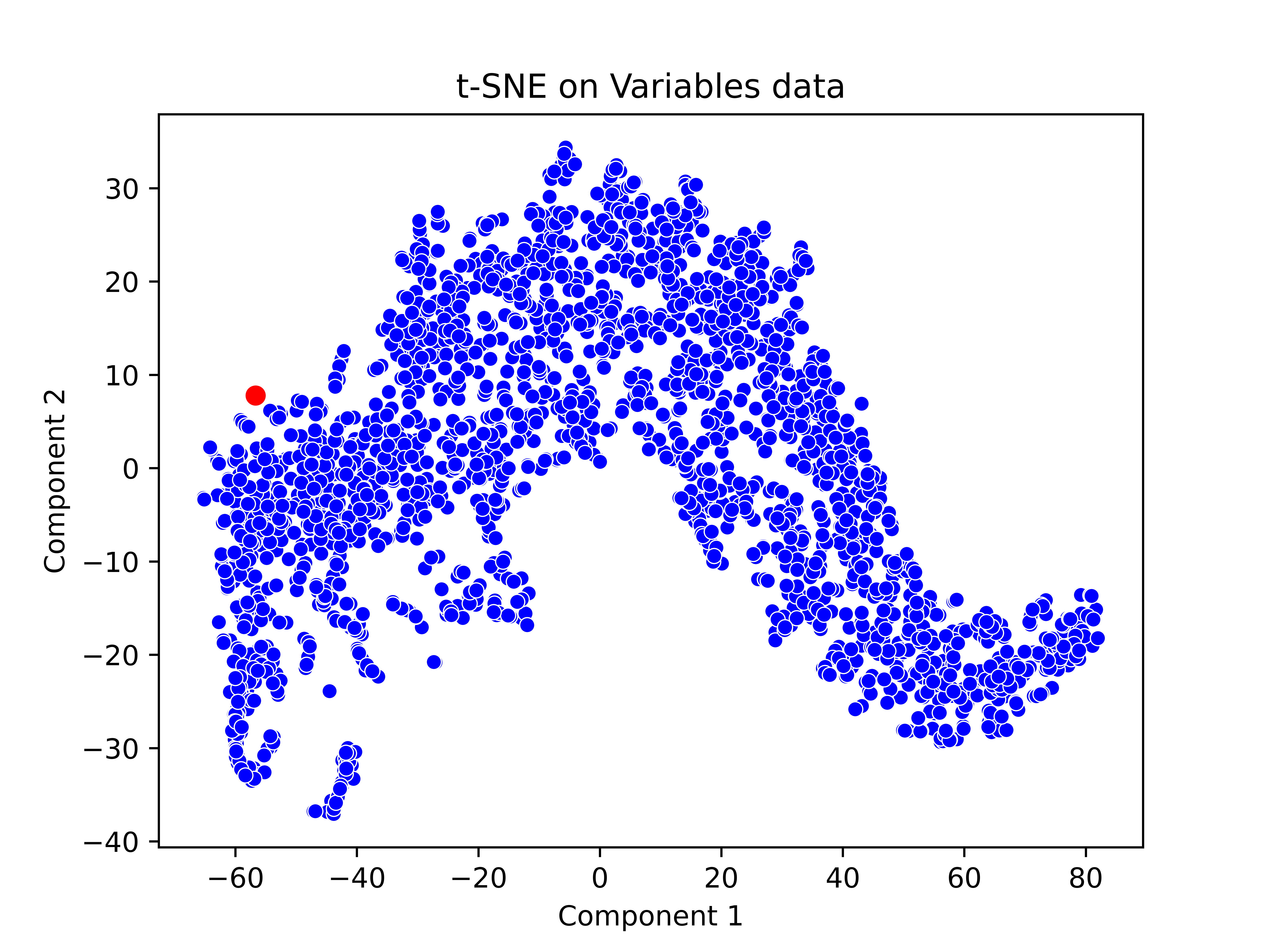
Figure 1
t-SNE visualization of the multi-dimensional dataset
Figure 1
Current state-of-the-art ML techniques
The traditional approaches reported in research literature for detection of financial misinformation use both supervised and unsupervised ML techniques, when known examples are available or not, respectively.
Supervised ML techniques like logistic regression, Bayesian Belief Network, support vector machines and Artificial Neural Network classifiers, along with ensemble methods to combine their predictions, have been trained and used for detecting fraudulent FS.
On the other hand, since known instances of financial misinformation are rarely available, other researchers have used unsupervised ML techniques like anomaly detection, clustering and self-organizing maps for this purpose.
Our research addresses several critical gaps that must be bridged to make these techniques practical and effective for auditors in real-life.
A new take on misinformation detection
TCS Research is developing machine learning (ML) techniques for smart auditing. Some of the objectives of this research include:
- Developing unsupervised ML techniques to identify FS that may contain misinformation.
- Generating a human-understandable explanation of where a given FS is likely to have misinformation, meaning identifying data elements within the FS that could contain inaccuracies.
- Extracting auditing knowledge from a corpus of audit reports and FS.
- Generating highly specific and actionable audit recommendations for forensic investigations.
- Assessing the quality of audits and he reliability of information in FS.
Several research papers have been published related to this research agenda.
In many real-life scenarios, any collection of FS with known instances of misinformation is not freely accessible, mainly due to the confidential nature of this data. However, a large historical corpus of unlabeled FS and audit reports from various companies over different years is often accessible, say with government agencies, stock exchanges, and even in the public domain (e.g., https://www.moneycontrol.com). There is no information indicating whether any of these FS contain instances of misinformation. Hence, as part of this research agenda, the focus is on developing unsupervised ML techniques to detect "suspicious” FS within the given corpus.
The FS for each company in a specific year can be represented using a feature vector. Each feature corresponds to a particular financial variable. Besides the financial variables outlined in the FS, it is also possible to compute certain ratios from the original features and include them as additional features. This approach allows the existing corpus of FS to be easily converted into a structured database of feature vectors (rows or records) within a table, where each record represents one FS of a single company for a particular year.
Many anomaly detection (AD) algorithms have been developed in ML literature, capable of automatically detecting “anomalous” records in an unlabeled database. The criteria for defining what constitutes anomalies are not predefined. The basic idea behind AD methods is to identify those records as “anomalous” that “differ significantly” (or “stand out as very different”) from majority of the other records in the database. Besides applying established AD methods, some novel model-based AD methods have been developed as part of this research. All these methods can be applied to the FS database. Each AD method identifies a small subset of records (FS, in this case) that are considered “anomalous”. The outcomes of various AD methods can be combined using variations of “majority voting” ensemble methods to improve the accuracy of detecting “anomalous” FS. The effectiveness of these methods in identifying “anomalous” FS within a specific corpus has been demonstrated on a real-world corpus of FS from 4,100 companies in India. For instance, one feature vector was flagged as “anomalous” (or “suspicious”) in this corpus by these AD methods. In fact, the auditors had previously raised several concerns regarding this FS; for example, regarding non-provision of depreciation for the year on Plant and Machinery and Buildings due to closure of plant on account of suspension of manufacturing operations and consequential overstatement of fixed assets and understatement of loss for the year by Rs. X Lacs.”
While it is beneficial to have automated methods that can identify a “suspicious” FS, it would be even more helpful if they could also generate explanations as to why a given FS is deemed “suspicious”. Several algorithms are available in literature that can generate such explanations. As part of this research agenda, an explanation generation algorithm has been developed, which outputs a subset of financial variables (features) as the “cause” of the anomaly in a given FS. For example, one possible explanation (among others) for why an FS might be labelled as “anomalous” could be that the Debt-to-Equity Ratio is unusually high (410.0) for this company when compared to other companies in the corpus (with an average value of 1.998 and a standard deviation of 41.75). Therefore, this feature is likely to reflect erroneous data or may represent an instance of misinformation.
It is important to note that the audit reports were solely employed to validate whether the predicted “anomalous” FS were indeed flagged by the auditors and were not used for the identification of “anomalous” FS.
A note of caution: Anomalies indicate potential, not certainty
It is important to note that identifying a FS as “anomalous” does not necessarily imply that the FS definitely contains some instance of misinformation. An auditor or forensic accountant usually examines a company’s FS in isolation, meaning they do not compare it with the FS of other “peer” companies. This may lead the auditor or forensic accountant to overlook some types of misinformation, which only become apparent when a corpus of FS is viewed as the context or background. Our approach assists auditors or forensic accountants in detecting instances of such misinformation by “pointing a finger”. Specifically, our techniques highlight specific FS within a corpus for further investigation; auditors or forensic accountants can apply their domain expertise to detect actual misinformation (if present) in those FS.
An obvious limitation of automated ML techniques in detecting and “explaining” misinformation in FS is that they rely solely on the data contained within FS, without incorporating any external data that auditors can access and verify, such as internal business systems and databases, trails of business processes, business reports, and communications with stakeholders (e.g., letters from banks). The effectiveness of ML techniques can be significantly improved if such data were made accessible to them.
Misinformation detection: The way forward for corporate governance
As misinformation and new forms of fraud related to it become widespread, financial institutions and government bodies must be vigilant and create effective strategies and processes to identify and prevent fraud stemming from misinformation. High-quality and efficient corporate governance is crucial for ensuring fairness and building trust among both internal and external stakeholders. One necessary step – often mandated by relevant laws – is to guarantee that FS are free from any kind of misinformation.
The methods for detecting misinformation in FS can also be applied to other financial documents, such as invoices, receipts, tax returns, and customs manifestos. The ability to detect misinformation in FS and various financial documents is beneficial for many critical tasks, including the early detection of fraud and unethical business practices, improved credit assessment, prevention of loan defaults, increased tax collection, improved corporate governance, better credit assessments, reduced business risks, and better screening of suppliers. These techniques can also help in early detection of financial mismanagement, negligence, irregularities, or misconduct within government organizations and welfare programs, thereby leading to improved governance, cost savings, and better delivery of welfare benefits.