Service
Artificial Intelligence

Building a Smarter, Connected Tomorrow with AI-first and Agentic AI
Highlights
- Agnostic validation enables transparent, explainable decision‑making for all artificial intelligence-machine learning (AI-ML) architectures, helping organisations overcome blackbox limitations and build trust in automated outcomes.
- Model‑agnostic validation strengthens ethical AI by identifying bias, detecting drift, and ensuring decisions remain justifiable and consistent, especially in high‑stakes domains like credit, insurance, and customer services.
- Integrated generative AI (GenAI) capabilities accelerate reporting and validation, offering semantic data checks, synthetic data generation, and standardised end-to-end (E2E) model reports for faster, high‑quality governance.
On this page
On this pageinpage
Agnostic model validation in modern AI
Agnostic model validation independently assesses if an artificial intelligence or machine learning (AI-ML) model is reliable, explainable, fit for its intended use, and critical to mitigate bias, instability, and regulatory risk in AI‑driven decisions.
While organisations increasingly depend on AI‑ML to drive decisions in high‑stakes domains, many models still function as opaque ‘black boxes’ because their predictions cannot be easily explained in terms that humans can understand, creating risks tied to explainability, fairness, and regulatory scrutiny.
A model‑agnostic validation framework resolves these challenges by applying consistent validation, interpretability, and monitoring practices on any model architecture—statistical, ML, deep learning, or generative AI (GenAI). This unified approach supports transparency, reproducibility, and readiness for global regulatory expectations such as SR 11‑7 (Supervisory Letter 11-7) in the United States, General Data Protection Regulation (GDPR) in the European Union (EU), Prudential Regulation Authority (PRA) in the United Kingdom (UK), Monetary Authority of Singapore (MAS), Personal Data Protection Commission (PDPC) in Singapore, and various guidelines of central banks.
The framework spans explainability, data quality checks, bias detection, overfitting and robustness assessments, documentation, version control, and dynamic updates. By enabling standardised validations, bias and drift detection, and stakeholder‑aligned explanations, it strengthens decision integrity and operational resilience.
Integrated GenAI‑assisted reporting further accelerates end‑to‑end documentation and auditability at scale. Through architecture‑agnostic governance, enterprises gain consistent, defensible, and transparent control over model risk across diverse AI-ML systems.
Regulatory alignment and framework scope
Regulators worldwide are tightening oversight (see Figure 1) as AI-ML systems increasingly influence customer and business decisions. Standards such as SR 11‑7, PRA, and GDPR stress fairness, transparency, nondiscrimination, and strong governance across the model lifecycle.
Supervisory expectations now demand clear data usage controls, robust validation processes, explainability, continuous performance monitoring, and full auditability. A model‑agnostic validation framework directly supports these expectations through transparent reporting, explainability techniques, key performance indicator (KPI) dashboards, and end‑to‑end documentation.
The framework is intentionally architecture‑agnostic, ensuring consistent controls across statistical, machine learning, deep learning, and GenAI models. Its scope includes explainability and interpretability, data quality checks, bias detection, overfitting and robustness assessments, and structured documentation with version control. Key outcomes include fairness assurance, bias detection, and readiness for regulations such as SR 11‑7, GDPR, PRA, MAS, PDPC, and central‑bank guidelines.
Additional benefits include defense against data drift, stakeholder‑aligned explanations, and GenAI‑driven, end‑to‑end reporting for scalable auditability and operational resilience.
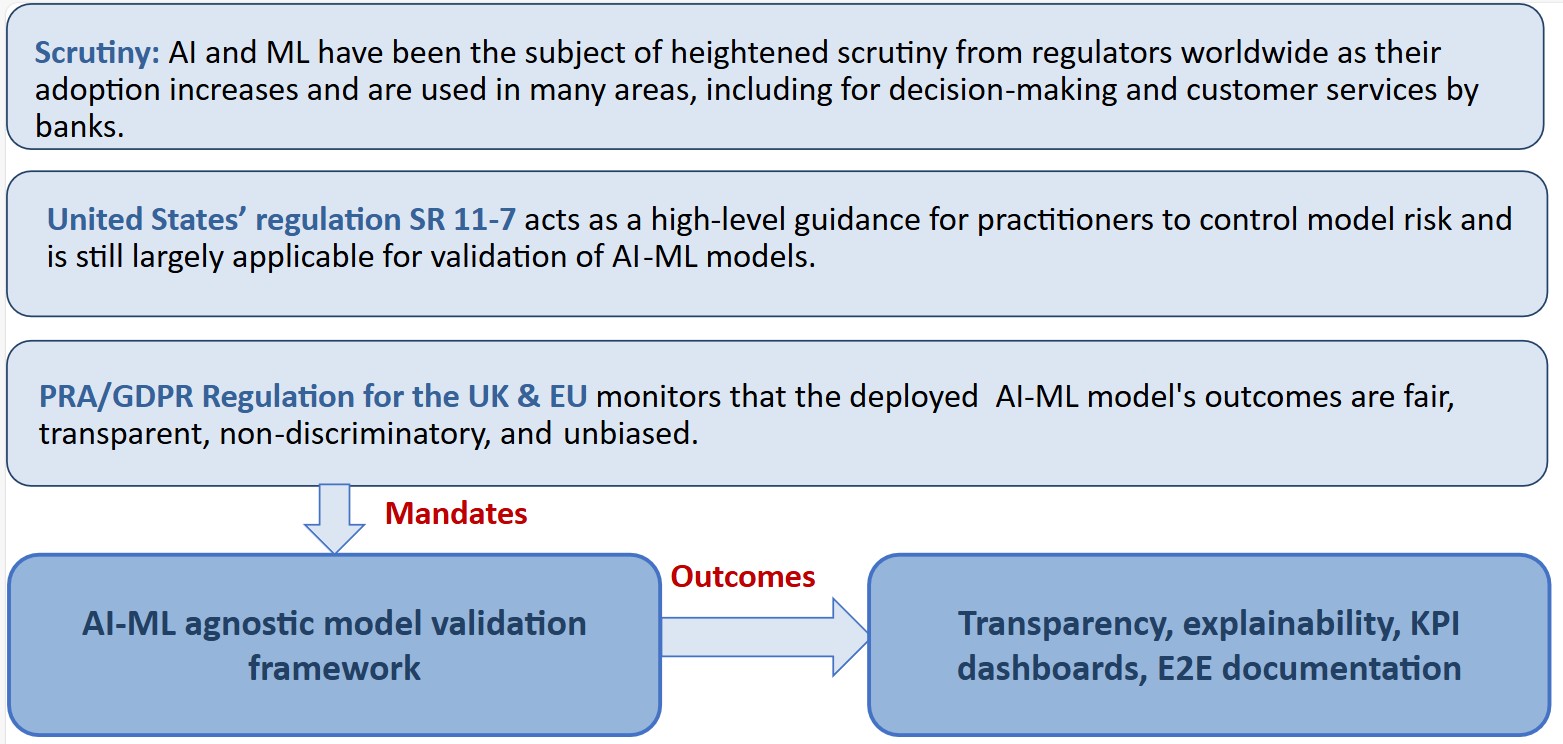
Figure 1
Regulatory expectations
Figure 1
Decision, integrity, and customer impact
Organisations increasingly depend on AI-ML models for high‑stakes decisions, yet the absence of model‑agnostic validation can leave both institutions and customers uncertain about how outcomes are generated. For example, in credit scoring, a loan request declined without a clear rationale reduces transparency and trust.
A model‑agnostic framework (see Figure 2) strengthens decision integrity by enabling explainable, justifiable, and ethically aligned outcomes. It also enhances regulatory compliance, improves robustness amid changing conditions, and reduces operational effort by minimising manual investigations.
It matters in practice because:
- Clear, consistent explanations build customer confidence
- Reliable decisions reduce remediation and escalation efforts
- Explainable outcomes support fair and ethical practices
Key challenges addressed
Financial institutions often rely on blackbox models, even as regulators demand greater clarity and accountability. Organisations must detect and mitigate bias, demonstrate fair treatment, and manage model or data drift through continuous monitoring. The framework embeds these needs by design, providing:
- Explainability for complex ML models
- Bias and fairness detection
- Drift monitoring and alerts
- Full audit trails and reproducible documentation
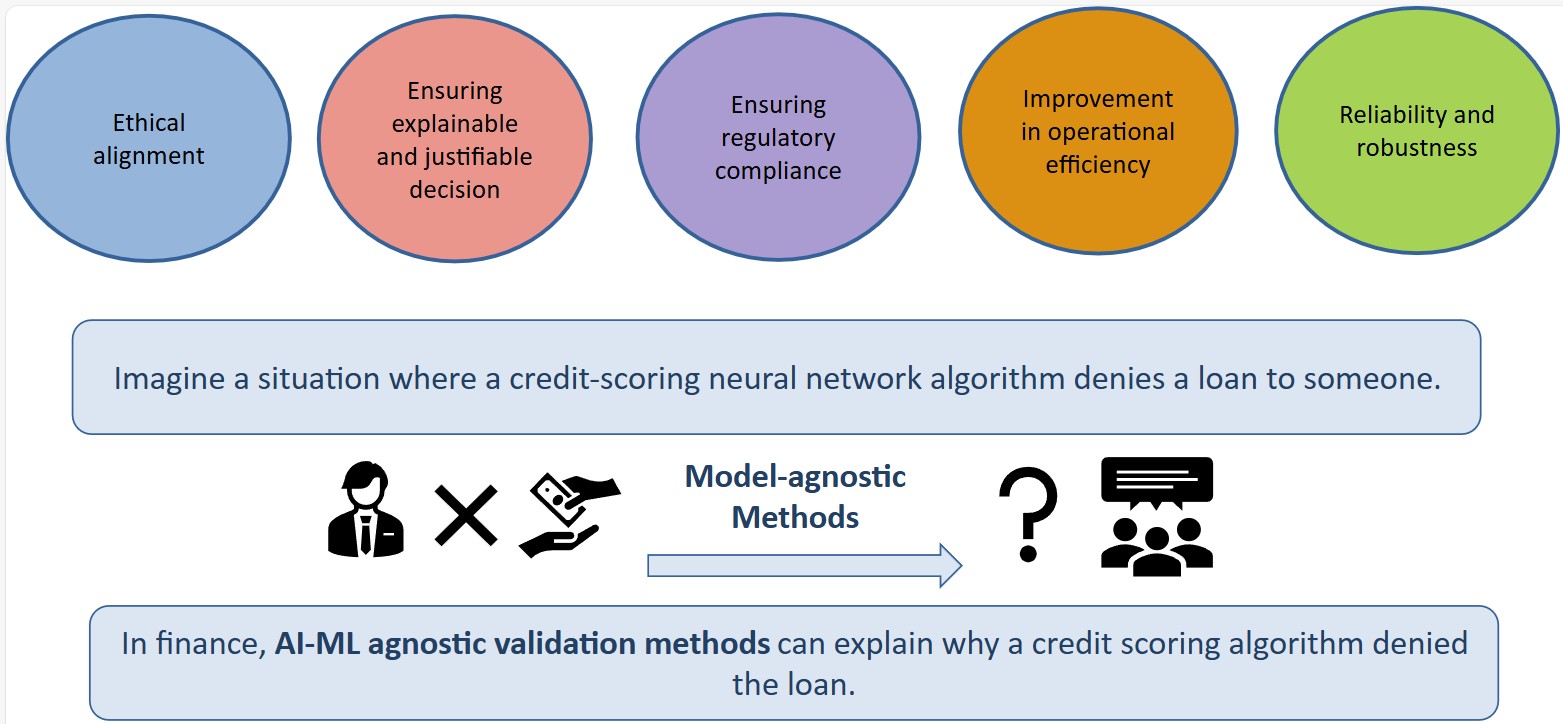
Figure 2
AI-ML-agnostic model validation framework
Figure 2
AI-ML model validation methodology
The methodology enforces disciplined assessment across data, features, models, and outcomes:
Validate merged, transformed datasets, sampling strategies, and filtering; traceability and data quality checks ensure inputs are reliable and reproducible. Outlier analysis and univariate, multivariate exploration inform variable inclusion or exclusion using ML techniques.
Acknowledge that neural networks and other complex models are difficult to interpret; use techniques (eg, LIME, SHAP, DeepLIFT, PDP) to identify how input features influence predictions and present results in a form stakeholders can understand.
Assess whether the model captures spurious patterns from training data; maintain holdout sets and apply cross‑validation, regularisation, learning curves, and grid search to calibrate complexity and generalisation.
Evaluate robustness to deviations from assumptions and monitor population, data drift. Methods indicated include XG Boost, Dynamic Learning, Isolation Forest, and LOF, coupled with domain adoption and drift detection procedures.
Use GenAI to cross‑verify low‑confidence outputs, generate synthetic data for boundary cases, perform semantic validation, deduplication, and produce E2E compliance reports.
This methodology provides a repeatable path to accountability, auditability, bias control, and fairness across any AI-ML model class (see Figure 3).
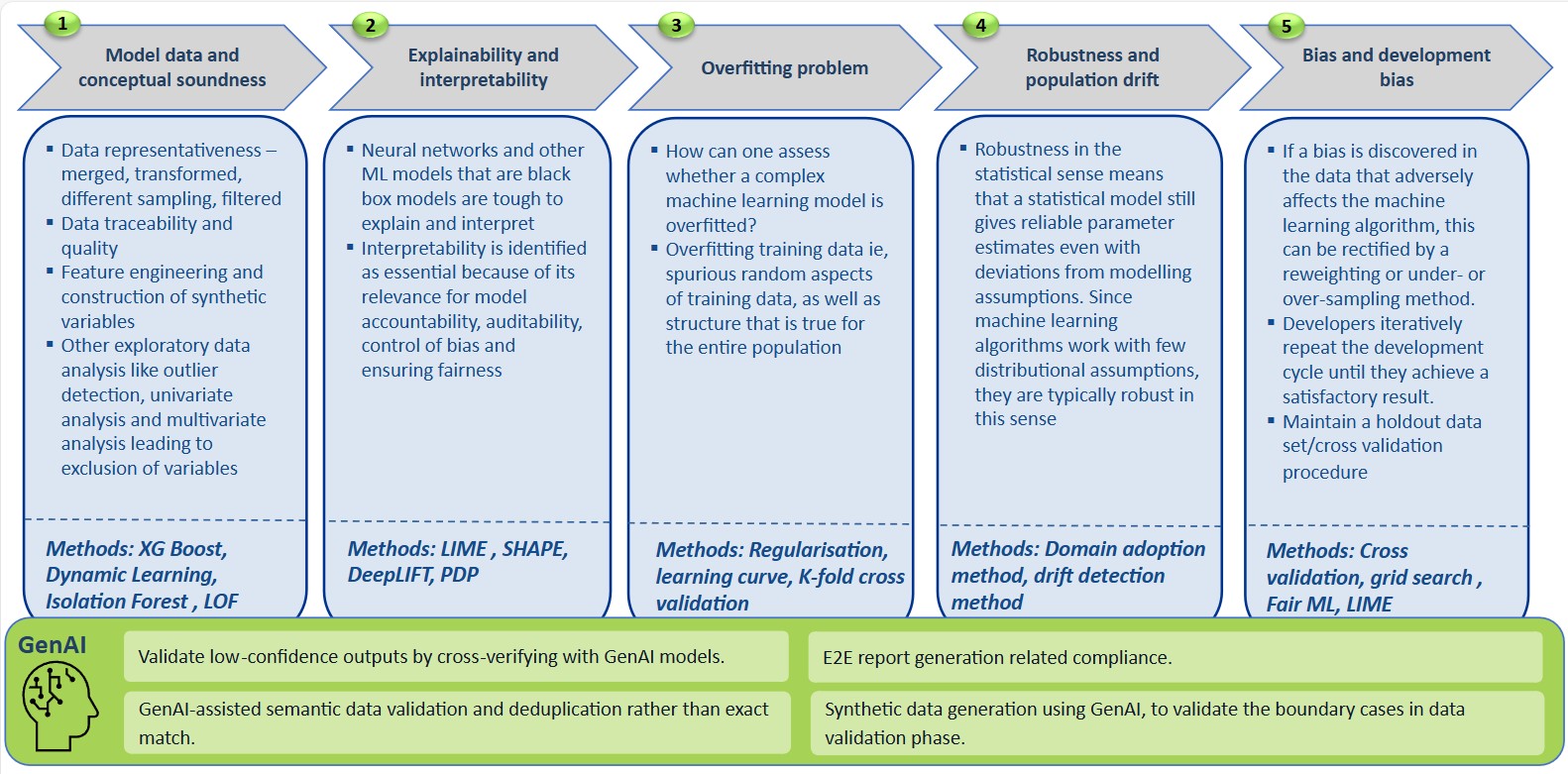
Figure 3
Validation methodology
Figure 3
Processes and checkpoints
The framework operates validation through explicit checkpoints:
- Problem definition: Establish goals for each model, define accuracy and fairness metrics, and set acceptable thresholds aligned to risk.
- Data sourcing and cleaning: Evaluate data dictionaries, labelling consistency, versioning, and data‑processing reproducibility (outliers, missing values, imputations).
- Feature engineering: Review encoding, stacking, ensembles, standardisation, scaling, binning, and dimensionality reduction or transformations.
- Model development and evaluation: Choose fit‑for‑purpose metrics; apply disciplined data‑splitting (train, validation, K‑fold cross‑validation), feature selection, hyper‑parameter tuning, regularisation, and champion‑vs‑challenger evaluation, including treatment of edge cases such as imbalanced data or sample shift. Explicitly assess accuracy‑fairness trade‑offs.
- Deployment: Enforce quality gates and release management backed by tested scripts and documentation.
- Monitoring: Track performance metrics, monitor input distributions and data drift, and establish alerting with periodic review of metrics and quality gates to sustain performance and compliance.
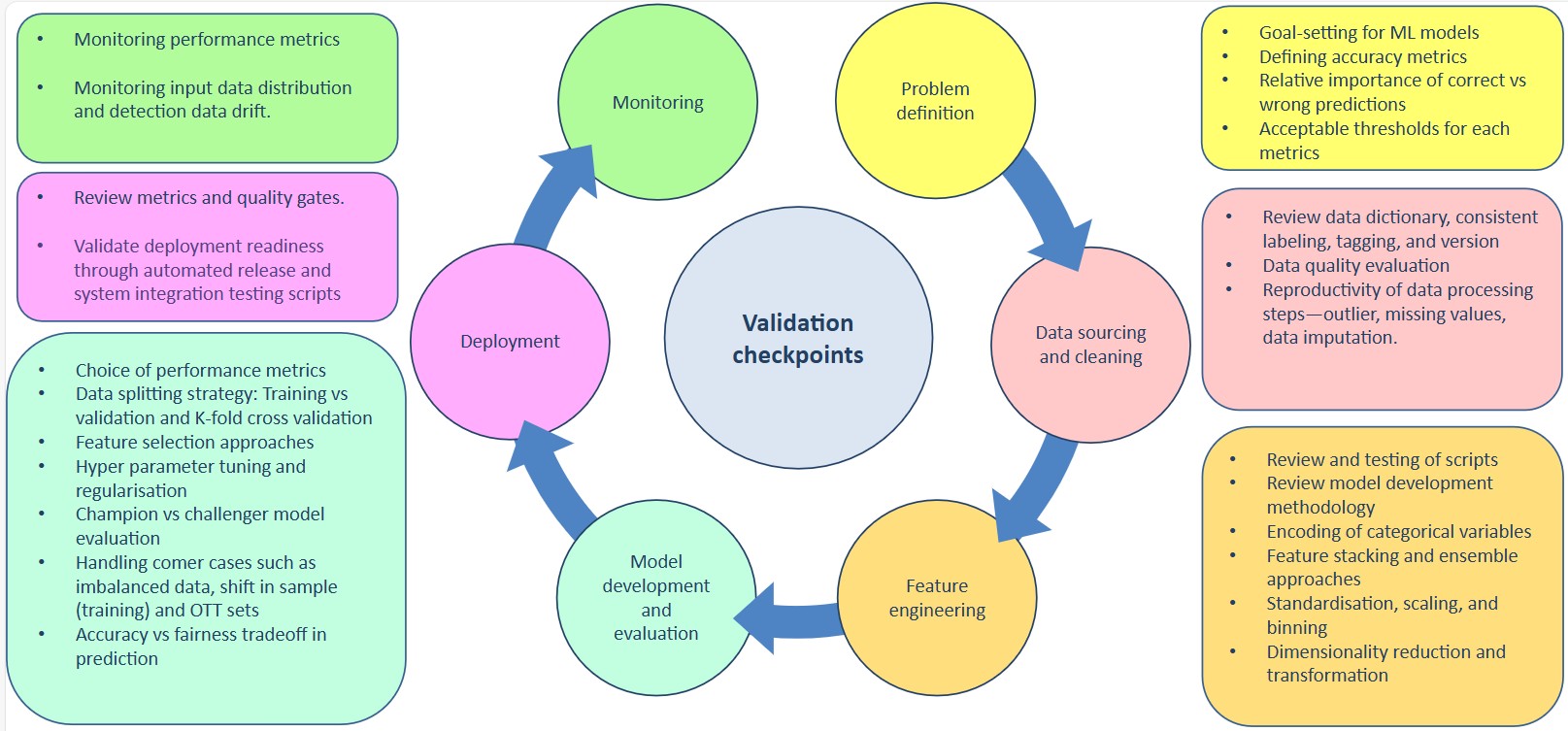
Figure 4
Validation framework
Figure 4
Dashboarding, reporting, auditability
A configurable, role‑based dashboard (see Figure 5) offers a comprehensive view of model performance, presenting key metrics, scores, and a built‑in compliance checklist to guide reviewers through required validation steps. Users can also download structured validation reports directly from the interface for audit or governance needs.
In addition, GenAI‑generated reports enhance this process by producing natural‑language summaries, explanation narratives, and timestamped logs of every validation activity, all available in standardised formats such as PDF, Excel, and JSON.
The reporting suite remains aligned with regulatory expectations, while real‑time drift monitoring and automated alerts ensure emerging issues are quickly identified and addressed.
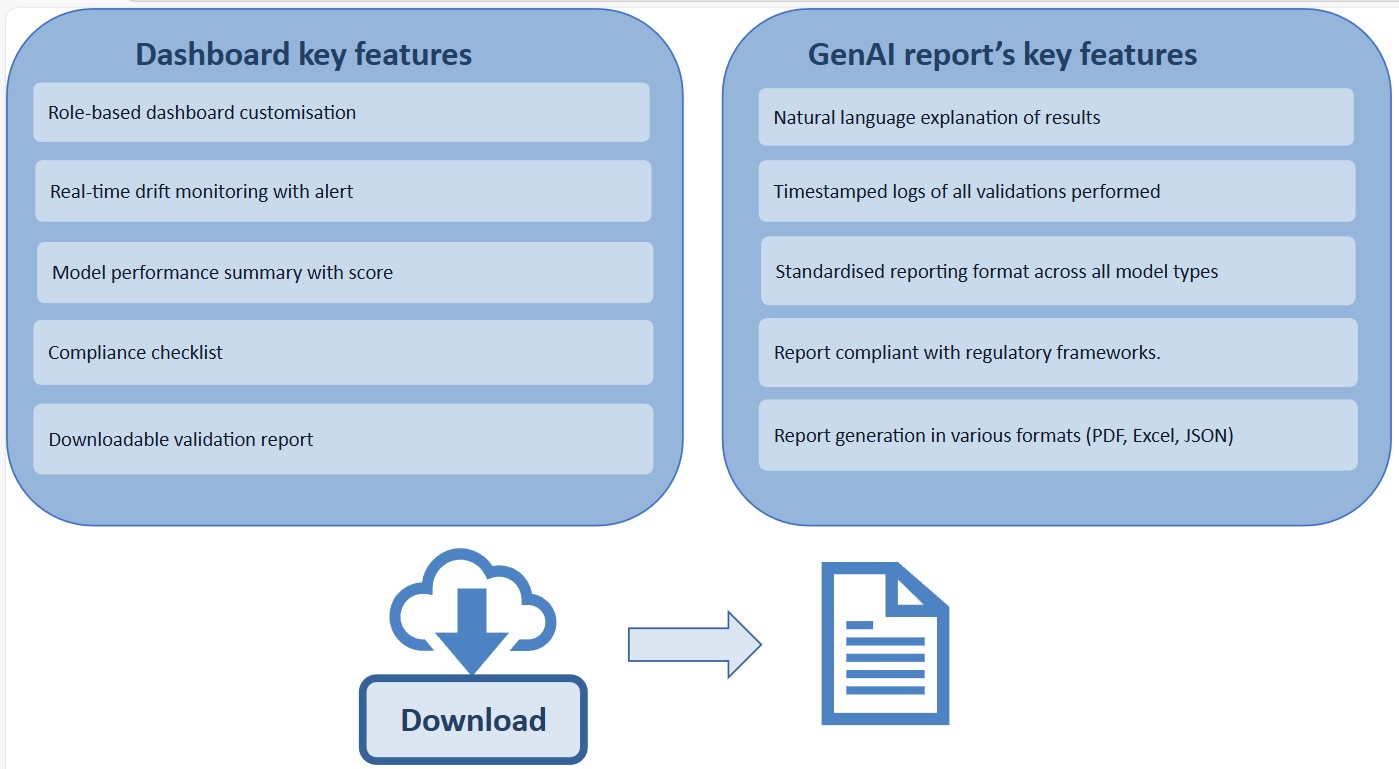
Figure 5
Dashboard and report
Figure 5
Framework highlights and business value
The framework supports statistical, machine learning, and GenAI models, enabling organisations to detect data drift, identify bias, and maintain consistent oversight across diverse AI architectures (see Figure 6).
It integrates seamlessly with existing enterprise ML and deep‑learning ecosystems, ensuring minimal disruption and maximum governance coverage. Designed to align with global regulatory expectations, including SR 11‑7, PRA, GDPR, MAS, PDPC, and various central‑bank guidelines, it is adaptable beyond banking to any industry where explainability is critical.
By offering GenAI‑driven end‑to‑end reporting and standardised validation workflows, the framework strengthens client partnerships, enhances stress‑testing and monitoring services, and provides scalable value across sectors with similar compliance and transparency needs.
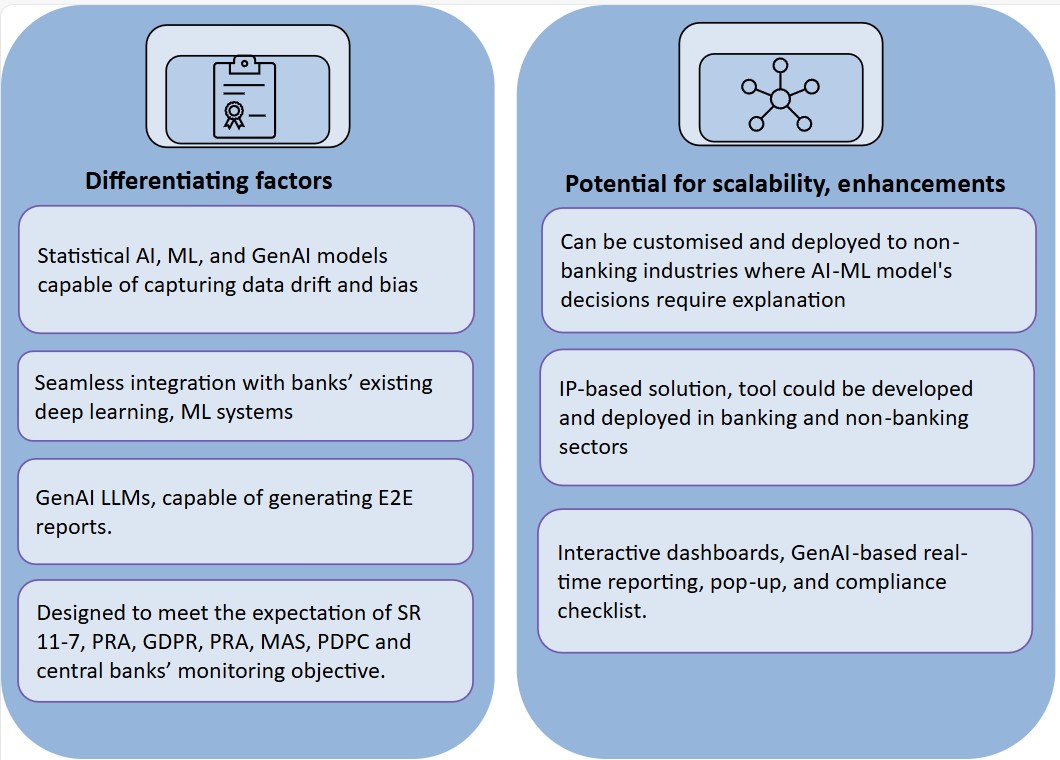
Figure 6
Framework highlights
Figure 6
Implementation road map
Execution can follow the framework’s own checkpoints as phased milestones:
- Mobilise and define: Confirm problem statements, target metrics, fairness thresholds, and governance roles.
- Data foundation: Lock data dictionaries, labelling, versions, and reproducible processing (imputation, outliers).
- Feature and model build: Apply standardised feature engineering, CV, regularisation, grid search, and champion‑challenger patterns.
- Explainability and bias: Operationalise LIME, SHAP (SHapley Additive exPlanations), DeepLIFT, or PDP, fairness tests, and accuracy‑fairness trade‑off reviews.
- Documentation and release: Enforce quality gates, scripted releases, and E2E documentation with GenAI‑assisted reports.
- Monitoring and drift: Activate dashboards, compliance checklists, logs, and real‑time drift alerts with periodic effective‑challenge reviews.
A model‑agnostic validation framework enables organisations to build AI systems that are transparent, fair, and resilient across evolving regulatory and business environments. By embedding explainability, bias detection, drift monitoring, and auditability by design, it strengthens trust and integrity in every decision. Ultimately, it equips enterprises to scale AI responsibly while safeguarding customer impact and compliance.