Services
Enterprise Solutions

Accelerate Enterprise Digital Transformation for Sustainable Change
Industry
Manufacturing

Future-Ready Manufacturing: Partnering in your journey to a sustainable manufacturing enterprise
Highlights
- Enterprises are increasingly leveraging next-gen application management services (AMS) to adopt new business models, elevate customer experience, and drive transformation.
- AMS partners are expected to transform to AI-powered service management to achieve significant cost reduction and ensure maximum operational efficiency.
- Intelligent IT operations management approach and framework can help make AI and GenAI integral for data driven insights, accuracy, and agility in operations.
In this article
OVERVIEW
The new dynamics of agentic AI will transform end-user experience.
With artificial intelligence (AI), machine learning (ML), and natural language processing (NLP) accelerating automation, there is a paradigm shift in customer interactions in the IT operations management space. Conversational bots and virtual assistants, enabled with agentic AI capabilities, have emerged recently that can beautifully interpret human inputs and generate contextually relevant responses.
Enterprises are increasingly leveraging next-gen application management services (AMS) in this area to adopt new business models for superlative customer experience and accelerated growth.
SOLUTIONS
As part of their next-gen AMS strategy, organizations are adopting intelligent solutions with real-time data-driven insights for better decisions.
An intelligent application management system, with AI at the core, streamlines operations and enables data-driven, smarter decision-making across the enterprise. Let us look at a few scenarios with AI-driven value propositions for AMS:
- Automated classification of incidents using supervised machine learning, based on historical data
- Business problem: Reading ticket details from a huge set of raw ticketing data is time-consuming and requires contextual expertise. The analysis approach may be corrupted by personal biases and end up being not standardized.
- Benefits: Improved decision-making, improved accuracy, and reduced time for SDM reporting.
- AI-based automation mining for systematic ticket categorization to understand automation potential
- Business problem: The absence of a standardized approach to ticket classification and trend analysis slows down the process of identifying the right automation or optimization that can significantly improve the accuracy and efficiency of AMS operations.
- Benefits: Improved decision-making and increased opportunity for automation.
- Intelligent ticket routing for machine learning based auto-categorization of tickets
- Business problem: Lack of contextual expertise often leads to incorrect routing of tickets. Based on data, roughly 10% of tickets for enterprise portfolios are often routed to incorrect support queues, leading to delayed resolutions.
- Benefits: Faster response and improved average handling time for incidents.
- Predictive intelligence and incidents volume forecasting for IT support
- Business problem: For large enterprise ecosystems with huge amounts of raw ticketing data, it is a constant challenge to identify patterns and outliers; foresee and account for disruptions in business processes.
- Benefits: Proactive and actionable insights, resource planning, and better forecasting.
- Predictive intelligence and prediction of MTTR of AMS incidents based on historical data
- Business problem: If incidents are not adequately monitored and measured, service operations would not have ML-based, MTTR predictability.
- Benefits: Improved maintenance strategy and support workforce management.
- AI predictive models, based on ML and NLP, for priority sensing and impact assessment of IT incidents
- Business problem: A significant 15% of incidents are raised with incorrect priority, thus carrying a risk of system downtime.
- Benefits: Proactive and actionable insights, fast identification and triage of critical incidents.
- Search intelligence, using NLP and pattern matching, for SOP/KEDB searches for quicker resolution of L1/L2 incidents
- Business problem: Manual intervention in searching for exact knowledge article from diverse knowledge sources is time-consuming and often leads to a sub-optimal issue resolution time for incidents even when there is prior knowledge and know-how on resolution steps.
- Benefits: Service delivery efficiency, faster resolution time, and improved MTTR.
- Cluster analysis to identify patterns and grouping similar issues via NLP and pre-trained learning models for prediction of major incidents by identifying fast-growing clusters of incidents
- Business problem: A critical issue could occur silently leading up to a major incident in business operations.
- Benefits: Proactive and actionable insights and reduced system downtime.
- AI-ML based clustering recommendations on parent-child relationships to match new incidents with existing clusters
- Business problem: Duplicate incidents being assigned to different service agents can cause huge inefficiencies, especially if all incidents pertain to the same underlying cause.
- Benefits: Service delivery efficiency.
How it works
Closed incidents with proven resolution are used as training data in a supervised method of service desk ticket classification.
1. Data pre-processing
The historical data to be used as training data should be critically analyzed to address any bias, missing data and noisy data.
2. Feature extraction
Feature extraction refers to the process of transforming raw data into numerical features that can be processed while preserving the information in the original data set. Before applying any machine learning algorithm an historical ticket dump needs to be converted into numerical representations. Python’s Scikit-learn's CountVectorizer is used to convert a collection of text documents to a vector of term/token counts.
To help with pattern recognition, an n-dimensional feature vector is created on ticket data using a frequency-inverse document frequency (TF-IDF) weightage process. In this numerical representation, each element of the vector, tagged with a TF-IDF value, represents distinctive words. It diminishes the weight of terms that occur very frequently in the document set and increases the weight of terms that occur rarely.
3. Classification models
Classification models like logistic regression, Random Forest classifier, Multinomial Naive Bayes, MLP and support vector machines, and LSVM are used along with ensemble models like stacking.
The architecture of a stacking model involves two or more base models, often referred to as level-0 models, and a meta-model that combines the predictions of the base models, referred to as a level-1 model. Linear models are often used as the meta-model, such as logistic regression for classification tasks.
Stacking models, trained on the predictions made by base models, can make predictions that have improved performance compared to any individual base model in the ensemble. The machine learning pipeline is used to automate the model building process.
4. Model evaluation
Stratified cross-validation is used to provide train/test splits in training a data set for evaluating each model. Finally, the model with best accuracy gets picked up for deployment.
K-Means clustering is an unsupervised learning algorithm that can categorize tickets data into K-number of clusters.
This is done by assigning data-points to clusters based on the distance from a cluster centroid. This applies ‘distance metrics’ which respectively combines Jaccard distance and Cosine distance for fixed data and free entities from incidents data.
Cluster labels are identified by mining and extracting logical item sets of each cluster and then performing semantic labelling.
In many scenarios ‘K’ is not explicit, and we need to analyze datasets to iteratively determine the optimal number of ‘K’.
- Contextual understanding: Generative pre-trained models are trained with huge amounts of human language data which enables them to understand the emotional aspect of a similar word appearing in different contexts. This awareness improves the accuracy of sentiment analysis executed by GenAI.
- Nuanced aspects: GenAI can identify subtle variations and nuances of emotions in data that may be missed by older methods.
- Handling sarcasm and irony: GenAI can recognize and interpret sarcasm and irony in conversations, which is a noted challenge with existing NLP-based approach.
- Multilingual analysis: GenAI models can address multiple languages, making these models more versatile for sentiment monitoring in a global context.
TARGET PERSONAS
In AMS, GenAI systems are a copilot for humans, not a replacement.
GenAI will augment, accelerate, and simplify the operational processes, always with humans in the loop. Based on experiential knowledge, we list relevant AMS use cases and target personas, and the potential benefits GenAI can bring to each
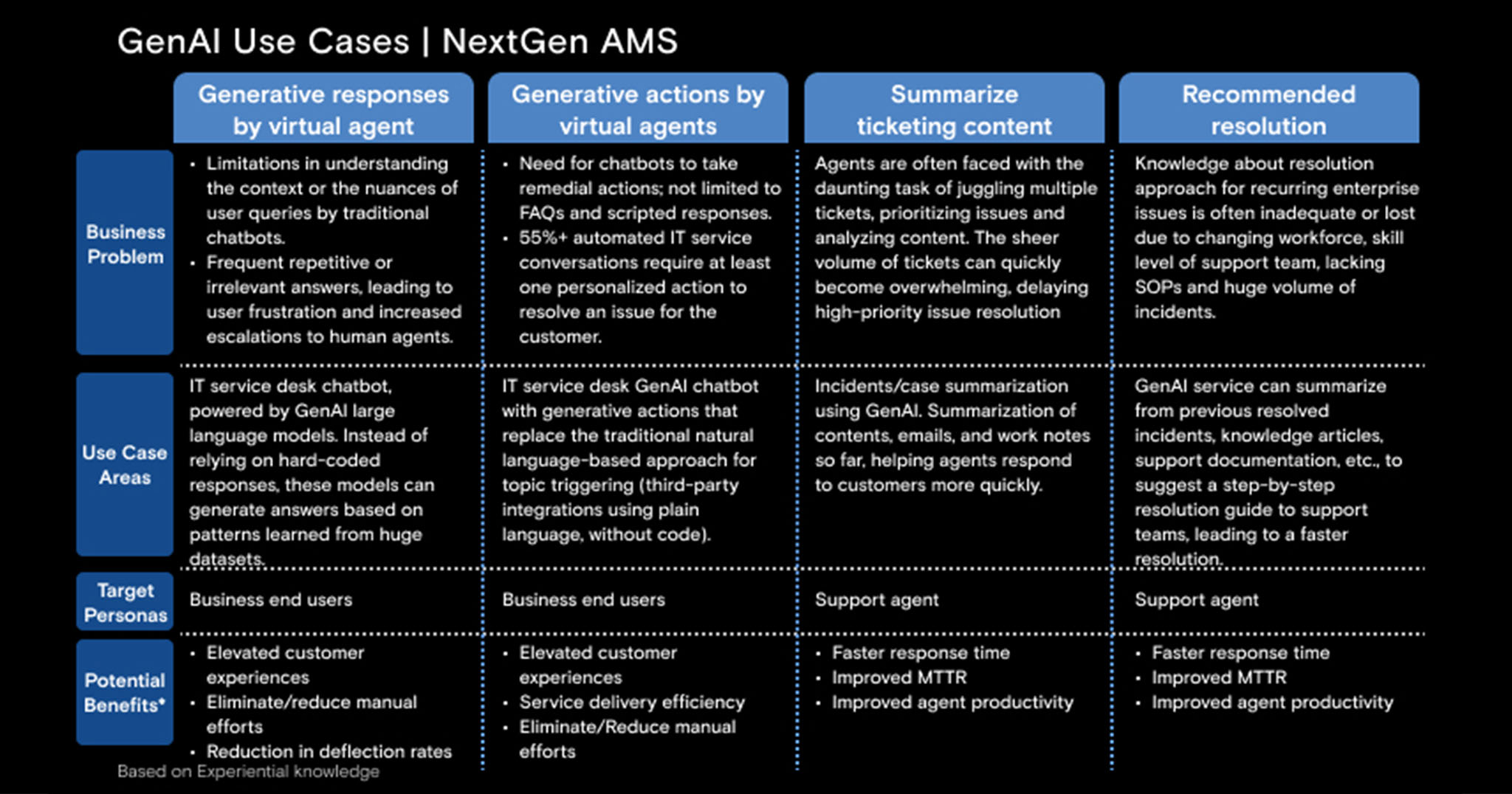
Fig 1: GenAI use cases for next-gen AMS
Fig 1: GenAI use cases for next-gen AMS
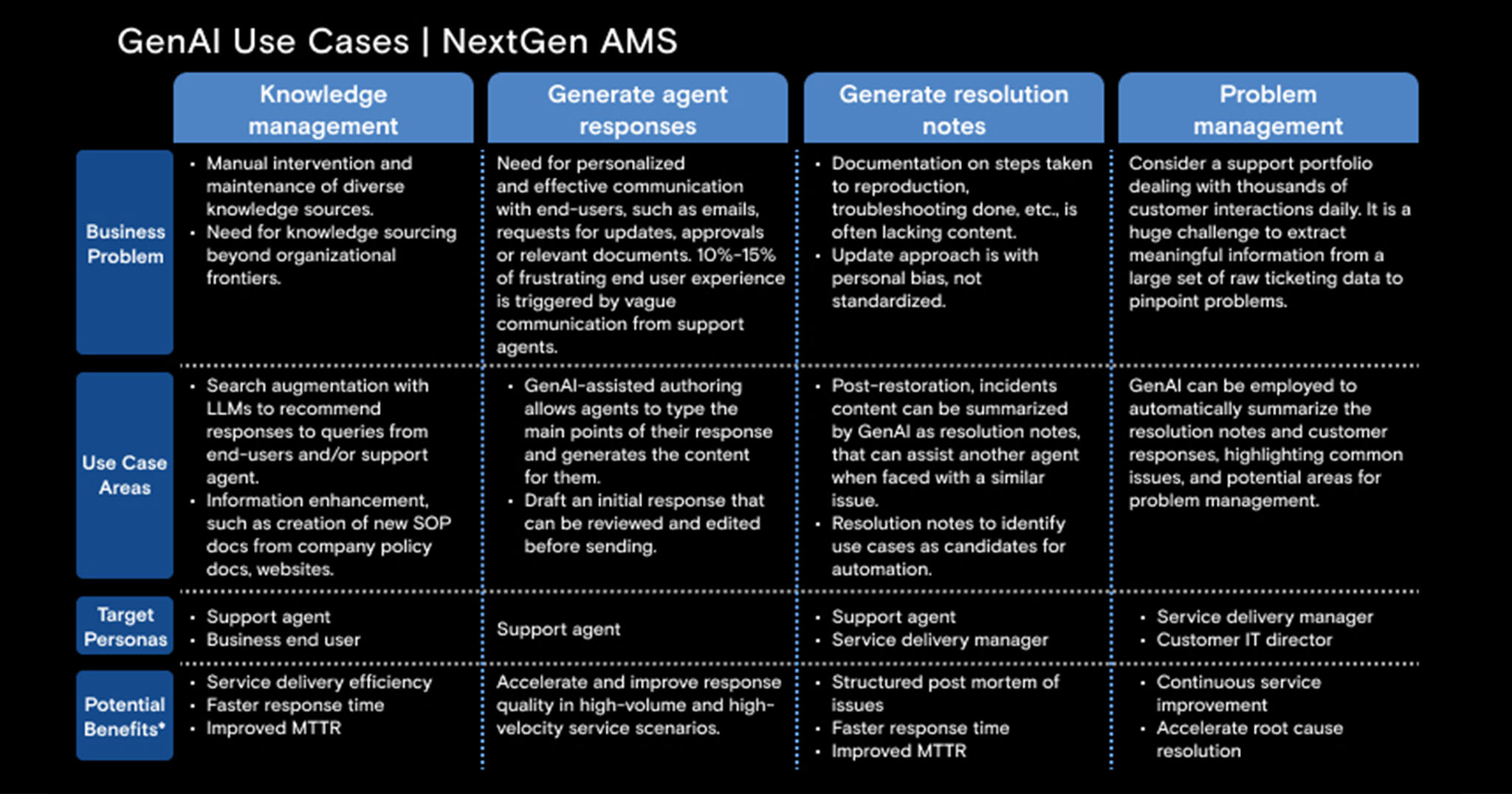
Fig 1: GenAI use cases for next-gen AMS
Fig 1: GenAI use cases for next-gen AMS
GENERATIVE AI SCENARIOS
Besides transforming service operations efficiency from Level 0 to Level 3, GenAI brings a whole lot of other benefits.
GenAI offers a wide range of impactful outcomes. We explore two high value use cases in the context of AMS operations.
Scenario 1 | Getting customer feedback and measuring satisfaction
Problem statement
- Roughly 10%‒15% of CSAT data is received against IT incidents.
- Traditional CSAT very often follows skewed distribution.
- Traditional rating-based customer satisfaction surveys do not generate enough insights for a service delivery organization to drive meaningful transformation in operations. A single quantified value often does not reflect the true customer experience and frustrations (if any).
Transformation with AI and GenAI
- With a GenAI chatbot, service agents can engage customers immediately after an interaction and capture the feedback while the service experience is still fresh in the customer’s mind.
- Deep-learning GPT models have a deep understanding of human language with nuances, making them very effective for sentiment analysis. Sentiment analysis from incident content can be used by service delivery managers (SDMs) in identifying areas for improvement and monitoring customer satisfaction.
- The service manager can use sentiment trends over time to see if customer satisfaction is improving.
Potential benefits
- Measurable improvements in CSAT scores.
- Accuracy and relevance of the feedback collected.
- Tailored service responses based on sentiment analysis.
- Elevated customer experience.
Scenario 2 | AMS team onboarding for both transition and steady-state support
Problem statement
- Onboarding procedures are typically manual and non-standardized.
- Based on our interactions with industry players, we have observed that support team onboarding often remains incomplete due to lack of contextual data.
Transformation with agentic AI
- Contextual insights by AI-ML.
- Real-time guidance with AI agents.
- AI agents to automate administrative tasks.
- Analyze individual profiles to create personalized onboarding journeys.
Potential benefits
- Faster support team induction.
- Overall service delivery improvement.
APPROACH
Enterprises can adopt a consulting-led approach to define agentic AIs trained with KPIs, intent, and context of their business persona.
Increasingly, enterprises are adopting focused, role-based AI agents over horizontal technical LLMs. These agents help with faster execution of everyday tasks, with more strategic KPI-aligned data insights for faster decision-making. Advanced large language models (LLMs), augmented with enterprise context, refine recommendations over time, adapting to new patterns and evolving operational needs.
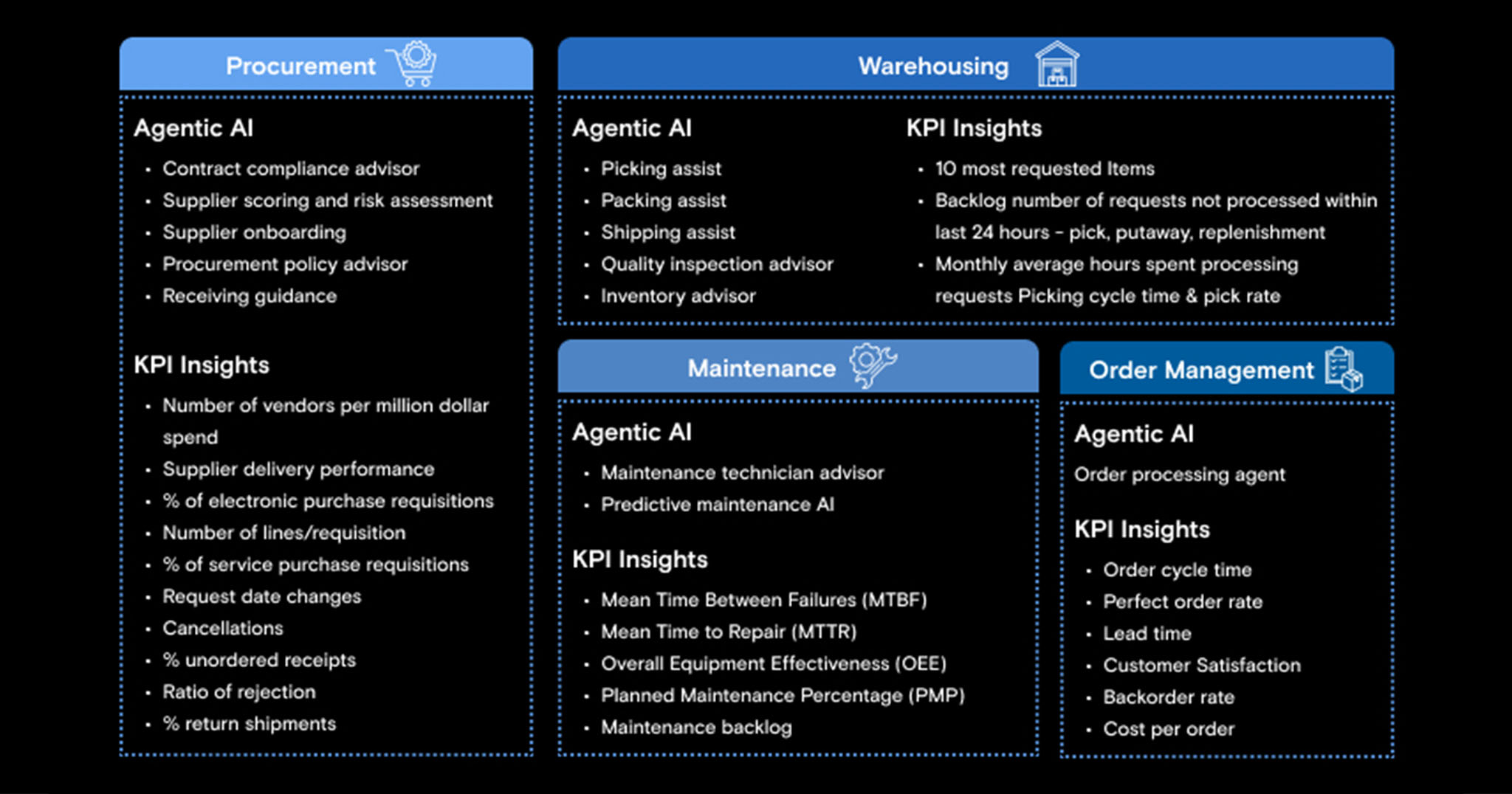
Fig 2: Using agentic AI in supply chain management
Fig 2: Using agentic AI in supply chain management
THE WAY FORWARD
The future of application management is intelligent, adaptive, and deeply aligned with business goals and KPIs – and AI is at its core.
As organizations evolve in a digital-first world, the integration of AI and GenAI into AMS operations is no longer optional. Organizations are harnessing AI-driven insights and automation to realize smarter operations, proactive issue resolution, business assurance, hyper-personalized user experiences, and greater agility.
- Generative responses by virtual agents: Rather than using pre-set or fixed responses, generative pre-trained transformer (GPT) models are creating adaptable replies based on data-patterns and contexts learned from large enterprise data.
- Improved ticket deflection rates: AI agents are effectively deflecting customer queries requiring IT intervention for providing training help, information clarifications, transaction or process statuses, and error notifications.
- Generative actions by AI agents: There is a rapid adoption of AI agents to take remedial actions; not limited to FAQs and scripted responses. In our experience, nearly half of automated IT service interactions necessitate at least one personalized intervention to effectively resolve customer issues. IT service desk virtual agents with generative actions that replace the traditional NLP method for topic triggering, are revolutionizing conversational approaches.
- Elevated customer experience with hyper-personalization: AI agents, equipped with personalization, is resonating with enterprise roles and individual preferences of users instead of generic interactions.