Service
Enterprise Solutions

Accelerate Enterprise Digital Transformation for Sustainable Change
Highlights
- Enterprises face brittle point‑to‑point integrations, siloed logging, and insufficient capacity across hybrid, cloud IT landscape, resulting in higher risk, operational costs, and non-compliance of service-level objectives.
- There is a need to make trusted data accessible to applications through seamless integration to meet evolving business requirements. For AI initiatives to succeed, these integration systems must be reliable enough to consistently supply the required data.
- AI can be used as one of the levers to improve integration reliability. Combined with closed-loop automation mechanism, it creates a system that continuously learns and improves reliability.
On this page
Why closed-loop automation
Across industries, operational teams are struggling to keep up pace with the evolution of modern enterprise IT systems–whether on-premises, on the cloud, or hybrid.
This is especially true when application programming interfaces (APIs), services, and infrastructure emit significant signals, making root cause isolation and safe remediation slow and error-prone.
Closed-loop automation replaces brittle, ticket-driven workflows with policy-governed feedback loops that act quickly to protect service-level objectives (SLOs), reduce mean time to recovery, (MTTR) and maintain auditability during peak load or rapid change.
Closed loop automation is an operating model for an IT landscape—like those powered by artificial intelligence (AI), for example—where systems continuously observe, decide, act, and learn, converting telemetry into safe, governed actions that improve over time. It relies on feedback loops that correlate signals across applications, integrations, and infrastructure, then triggers actions guided by policies and risk thresholds.
In this model, the business intent is encoded as guardrails—SLOs, compliance rules, and change policies—to ensure speed never compromises control.
The level of autonomy can be graded from recommendations (assistive) to fully automated remediation (autonomous), with a human approver where risk is high and/or confidence is low.
The pre-requisites for the model include modern observability (unified logs, metrics, traces, and events), standardised runbooks (codified response steps), and clear SLOs (targets for availability, latency, and error budgets). The result is a shift from dashboards and alerts to decisions and actions, reducing the MTTR and operational efforts. Over time, the system learns from outcomes, improving the precision, timing, and scope of actions.
As middleware becomes an enterprise’s nervous system, using closed-loop automation results for integration platforms results in trustworthy data that is reliably available across the enterprise.
The two‑way flywheel—Integration for AI and AI for integration
Integration for AI ensures that AI has timely, trustworthy data via resilient APIs, and events, and that streaming pipelines are relevant and contextual.
It keeps features current, reduces drift, and enables real‑time inference by delivering data with predictable latency and lineage.

Integration in the Agentic Architecture
Integration in the Agentic Architecture
AI for integration uses predictive analytics and machine learning to detect anomalies, forecast capacity, optimise routing, and auto‑remediate failures in gateways, queues, and workflows. This is often achieved via a hierarchical mesh of task-focused AI agents that are managed by orchestration AI agents.
As integration becomes more resilient, AI quality improves; as AI gets better, it further strengthens integration reliability—thus creating a positive feedback loop.
This flywheel increases business agility by reducing operational friction during change, scaling, and incident scenarios. It also compresses cycle times from issue detection to correction, improving the customer experience underload and during peak events. The result is a compounding advantage: better data results in better AI, which leads to better operations, which then ensures better data.
A layered integration reference architecture with AI for IT Operations (AIOps)/agents
A practical integration blueprint spans layers.
Starting from sources (systems of record and engagement) to an integration fabric (APIs, message buses, event streams), it encompasses observability (telemetry collection and correlation), AIOps/agents, and finally an action plane (execution of changes) also. The data plane carries business traffic, while the control plane enforces policies, governance, and guardrails across environments. Closed‑loop decisions typically execute at API gateways, integration platform as a service (iPaaS) runtime, service meshes, and robotic process automation (RPA) bots—where actions like throttling, rerouting, scaling, and failover can be safely performed.
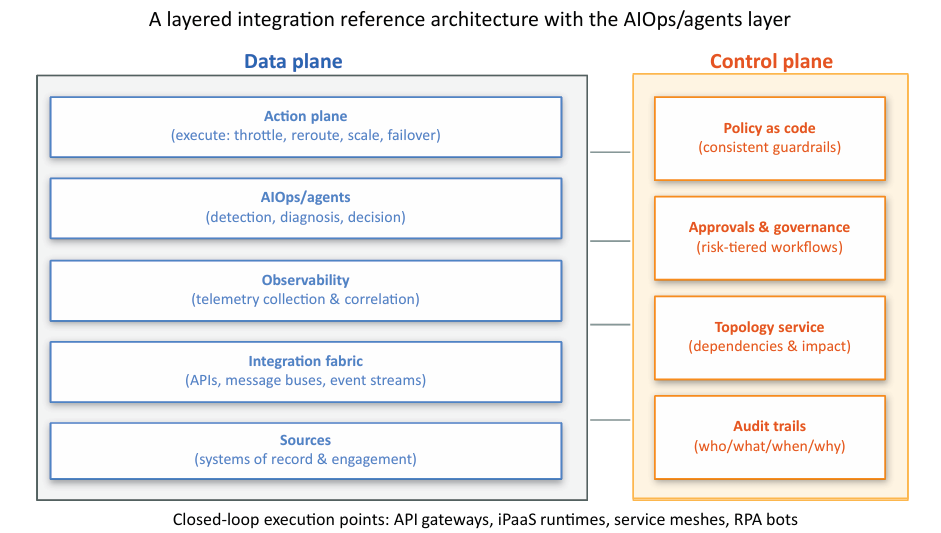
Closed loop execution points
Closed loop execution points
Policy as code ensures consistency across teams, regions, and clouds, with approvals integrated for higher‑risk moves. Audit trails capture who decided what, when, and why—supporting compliance and continuous improvements. The architecture is modular, enabling incremental adoption without a wholesale rewrite.
Why trusted data is the foundation for AI and integration
Trust begins with reliable data sources and volume handling via APIs, events, streams, and batch pipelines engineered to scale.
Governance spans cataloging, lineage, retention, and stewardship so teams know what data exists, where it comes from, and who owns it. Lifecycle controls define how data is created, transformed, archived, and deleted, reducing risk and storage costs. Privacy and security are enforced through encryption, role‑based access control, tokenisation or masking, and policy enforcement aligned to regulations. Quality checks and observability validate timeliness, completeness, and accuracy before data is used by AI models for operational decisions.
This foundation underpins both Integration for AI and AI for Integration, ensuring decisions are fast and trustworthy.
Challenges in enterprise integration
Enterprises face technical debt with brittle point‑to‑point connections that slow change and increase incident risk. As integration platforms work between applications and platforms, identifying true root causes from incidents and alerts stretch MTTR as handoffs multiply. Signals live in silos—logs, metrics, traces, and tickets—making it hard to reconstruct incidents or assess impact and lineage. Capacity is often reactive, leading to over‑provisioning costs or outages during high volumes. Compliance adds manual overhead for approvals, evidence, and audit trails, further slowing delivery. Hybrid and multi‑cloud deployments increase complexity across networks and data boundaries.
The net effect is higher cost to serve, slower velocity, and avoidable risk—areas where closed‑loop automation and AIOps can help.
What Is AIOps?
AIOps applies machine learning and advanced analytics to operations data to detect, predict, and remediate issues.
AIOps focuses on the run state—health, reliability, performance, and resilience. It complements observability by not only collecting telemetry but also interpreting it to surface causality and recommended actions.
Core capabilities include anomaly detection, event correlation, forecasting, change risk scoring, and policy guided automation. AIOps ingests logs, metrics, traces, configurations, topology graphs, and runbooks, creating a knowledge layer that understands how systems behave and relate.
When integrated with the action plane (in the previous architecture diagram), it can trigger targeted, auditable responses that compress MTTR and protect user experience. Over time, it learns from outcomes, improving accuracy and confidence levels.
How AIOps addresses integration challenges
AIOps reduces noise by correlating related alerts across APIs, services, and infrastructure, isolating the probable root cause quickly. It forecasts hotspots, informing pre-emptive scaling, rate limits, or routing before users are impacted. It scores change risk and recommends safe rollbacks or progressive delivery to contain incident impact.
Runbook automation turns recommendations into consistent actions such as restarts, queue drains, retries, or failovers, all governed by policy and approvals. SLO guardrails trigger automated throttling, rerouting, or graceful degradation when indicators move toward breach.
The result is lower MTTR, fewer incidents, and more predictable releases. Financially, this translates into lower cost to serve and improved return on investment (ROI) from integration platforms.
TCS’ Boomi AI agents for AIOps
TCS has developed Boomi AI Agents for AIOps, leveraging the ever-evolving Boomi platform capability spanning the entire spectrum of integration, data, API and AI.
These agents work in the AIOps/agents layer and provide actionable inputs to the action layer. The agents are depicted below on the agent autonomy scale.
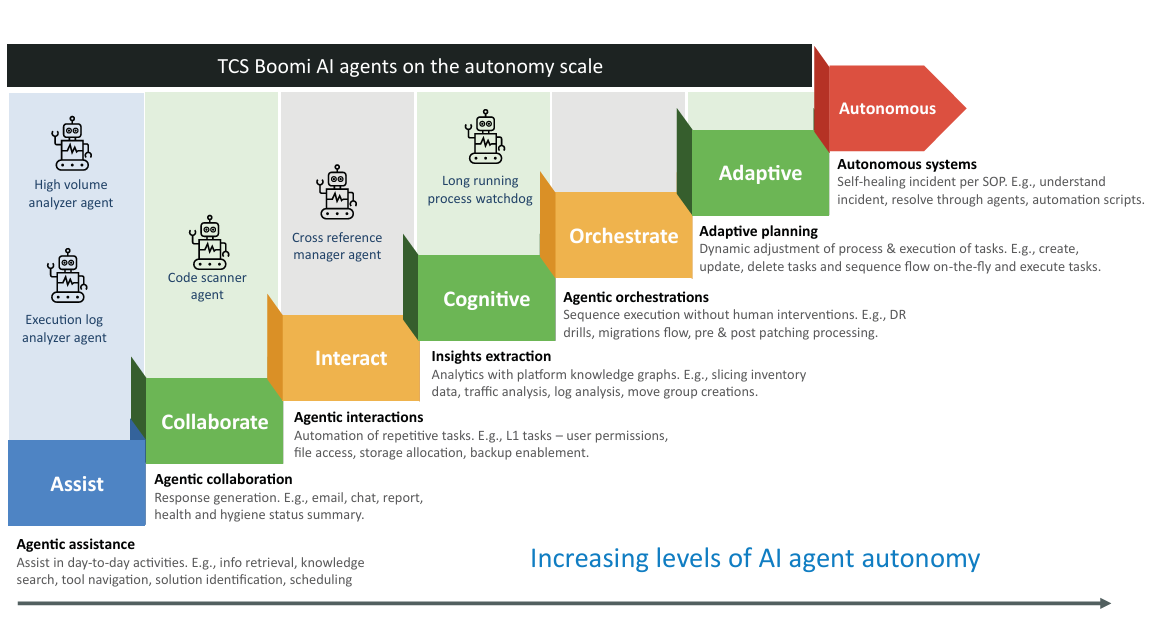
Increasing levels of AI agent autonomy
Increasing levels of AI agent autonomy
The ‘long‑running process watchdog’ monitors Boomi processes, identifying hung steps, compensating transactions, or stuck states and initiating safe recovery.
The ‘cross‑reference manager agent’ helps manage entries in a cross reference table (CRT). It simplifies the process of adding or updating entries in the table and supports updating specific columns within a row. Row deletion is also supported.
The ‘code scanner agent’ analyses Boomi integration code, mappings, and policies to flag security gaps, anti‑patterns, and deviations from standards before they hit production.
The ‘high‑volume analyzer agent’ learns normal traffic patterns and detects throughput anomalies or bottlenecks across Boomi runtimes. The agent allows users to identify high-volume executions based on document count, document size, or a combination of both.
The ‘execution log analyzer agent’ identifies executions that failed due to specific errors and supports these key actions: retrieve execution logs filtered by error message or process name within a defined timeframe.
Together, these agents cover prevention, detection, diagnosis, and remediation—closing the loop. They also produce audit artifacts for compliance and post‑incident learning.
In conclusion, bringing together trusted data, enterprise integration, and AIOps creates a governed, self‑improving operational model—better data → better AI → better operations → better data. As AIOps agents mature, organisations systematically reduce noise, shrink MTTR, and harden resilience—turning operations into a strategic advantage.